這一篇我們會來介紹在AWS上運行ML時有哪些AWS的服務是來支援我們運行我們的 ML的。
Storage
這裡我們會介紹AWS的三種在AWS ML會用到的stroage,分別是
AWS S3
S3提供了三種介面(APIs/SDKs/Web UI)供我們來操作S3。會使用到S3是我們在操作ML時會從S3拿取或儲存各式各類的 training file format。例如:CSV/ Parquet tabular data/ image/audio/video等等object data。並且S3能輕易的與其他AWS服務來整合。
在我們看S3在整個AWS ML中那些地方會使用到之前,我們需要認識一下其核心概念。
一個bucket是侷限存放在某一個region.我們在create bucket時可以選擇離我們最近的region(如香港,日本等),以減少網路的延遲性。
在bucket中,每一個檔案都有一個獨立的URL。舉例如下:
https://jasonkaobuckets.s3.amazonaws.com/mykey/jasonobject.doc,
其中 jasonkaobuckets是 bucket name, mykey/jasonobject.doc是key , jasonobject.doc是 object name。
AWS S3 具有多種功能,可讓我們在一個集中位置有效地管理我們的資料。但一個object最大檔案大小可以到5TB, 而且我們可以在稱為 object tags的功能中為每個object加到最高10個 key-value pairs, 而這個可以在object產生之後任意的修改。以下還有其他S3的重要功能。
而以下為S3的一些security功能
AWS EFS
AWS Elastic File System(EFS)提供全託管,POSIZ-compliant, 彈性的NFS filesystem。EFS設計成是PB等級,而當我們在這上面新增或刪除檔案時,它是自動的增長或減少(shrinks)其大小。EFS同時支援 authentication, authorization,encryption at rest/ in transit。通常啟用EFS的方式如下:
EFS的mount target可以在一個region裡的所有zone看到並被掛起來。所以在一個VPC裡,我們的EC2不管在哪一個zone都可以掛載在同一個mount target.
AWS FSx for Lustre
FSx是一個全託管,高效能的filesystem且是使用在大規模的ML作業與HPC(high-performance computing).FSx提供兩種filesystem,一種是給Windows,一種是給Lustre.給Lustre是基於普遍的Lustre filesystem,這是一種使用在分散式運算(例如ML)與 HPC. Lustre支援數百PB的資料與幾百GB aggregate起來的throughput.
在 AWS中,FSx是容易設定並且給ML的,大概會長得像如下的模式: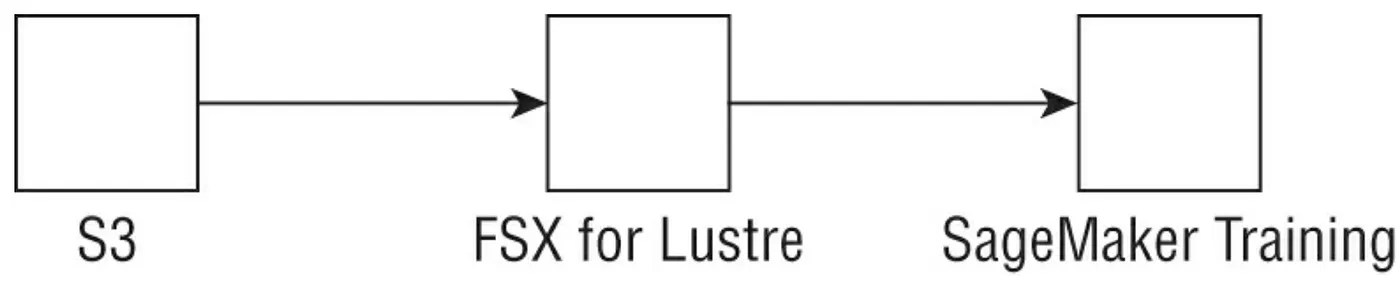
如上圖我們看到的,FSx for Lustre能夠連接既有的S3 Bucket並且自動的update有變動object的檔案跟目錄。FSx 充當 S3 中所有檔案的 POSIX 相容的front end,這個front end可以被任何Linux 系統跟container access。FSx可以直接與SageMaker整合用於訓練我們的模型.
小提示:
如果我們要對在S3上TB的等級的資料做大規模分散式訓練。 使用 FSx是非常好的選擇,因為我們不用一直從S3重複下載這些資料到SageMaker training instance。
Data Versioning
什麼是data versioning? 為什麼我們需要它?
開發人員與ML從業者已經非常熟悉使用類似 Git來作為代碼的版控.通常這一類的代碼版控是無法儲存大量的training datasets或已經訓練好的Model。而在AWS上,代碼的版控適用全託管的codeCommit(想成私人的GitHub)。使用多個file組成project code的project collaborating的典型工作流程包括添加需要追蹤的file、commit對file的變更並將這些變更推送到集中儲存庫,其他人可以從中pull change,branch out 我們的project 、merge new features等。 假設我們有一個如下所示的project folder: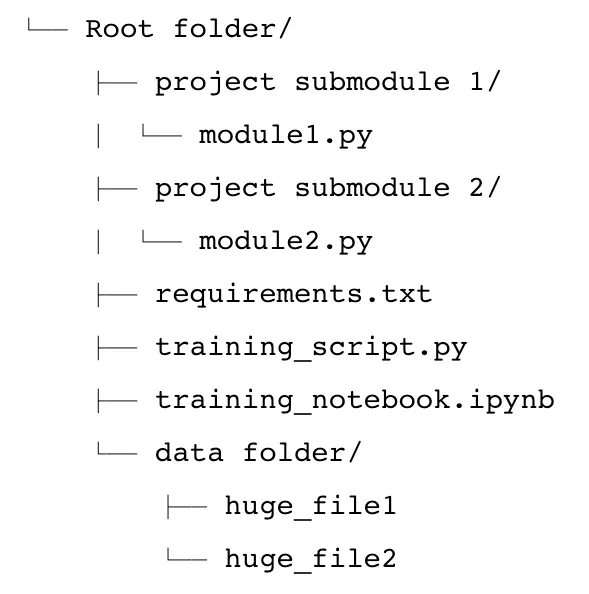
這裏顯示的是一個典型的project架構;它包含了主要的training script,一個可以用於exploration的notebook, 一些自定義的submodules, 一個定義額外package需要run的project files/data folder的requirement.txt檔案(這個data folder包含兩個大型的input file)。使用相同Git 方式的版本控制來上傳這些data file不是一個good practice;事實上,CodeCommit 每個file有 6 MB 的限制,因此可能無法對這些大的file進行版本控制。這就是 DVC 等data version control工具可以有生存空間的地方。
DVC 用於通過使用熟悉的工具和 AWS 後端存儲服務(如 S3 和 EFS)來追蹤、版控、備份和回復資料集的快照。 DVC 使用local cache,也可以使用 EFS 等服務在使用者之間共享,並且可以使用 S3 作為永久存儲。對資料集進行版控被認為是最佳實踐,但其他因素(例如當前stack的限制或缺乏適當的training)可能會限制了我們將 DVC 等工具整合到工作流程中。我們可能會問為什麼我們不能簡單地使用不同名稱的bucket或 S3 versioning來進行資料版控。這類似於詢問為什麼我們不能使用不同名稱的folder進行代碼版本化— — 這並不是強制按照設計執行最佳實踐。通過允我們使用結構化方法branch、commit、merge和使用datasets,versioning systes超越了這一點。
AWS VPC
VPC可以讓我們在一個我們所定義的logical virtual network發起 cloud resource。我們在此不多做介紹甚麼是VPC的基本概念(subsets/security group等)。因為我們假設這些都是讀者已經很熟悉的,若是不熟可以參考AWS 有關於VPC的文件。這邊有介紹的一個比較重要的概念是VPC endpoints,這是讓我們在VPC裡的AWS service可以透過AWS內部網路去連結AWS一些原來是Internet service(如S3),而無須走Internet(走Internet gateway/ NAT等)方式連線;而將提高網路效能與安全性。
一些AI與ML服務允許我們在實現一些功能在VPC裡使用具安全性的 VPC Endpoint(稱為AWS PrivateLink)。當我們建立VPC endpoint type時,它將會建立一個ENI(Elastic network interface)在我們的VPC subnet中,並帶有private IP。這個 private IP用作對AWS 服務的 API calls的entry point。例如,我們可以使用如下圖所示的interface endpoint來執行對 SageMaker 和其他服務的 API calls。 某些服務(例如 AWS Personalize 和 AWS Forecast)不支援 S3 VPC gateway,因此指向僅允許 VPC traffic的buckets中的training data將導致 AccessDenied error。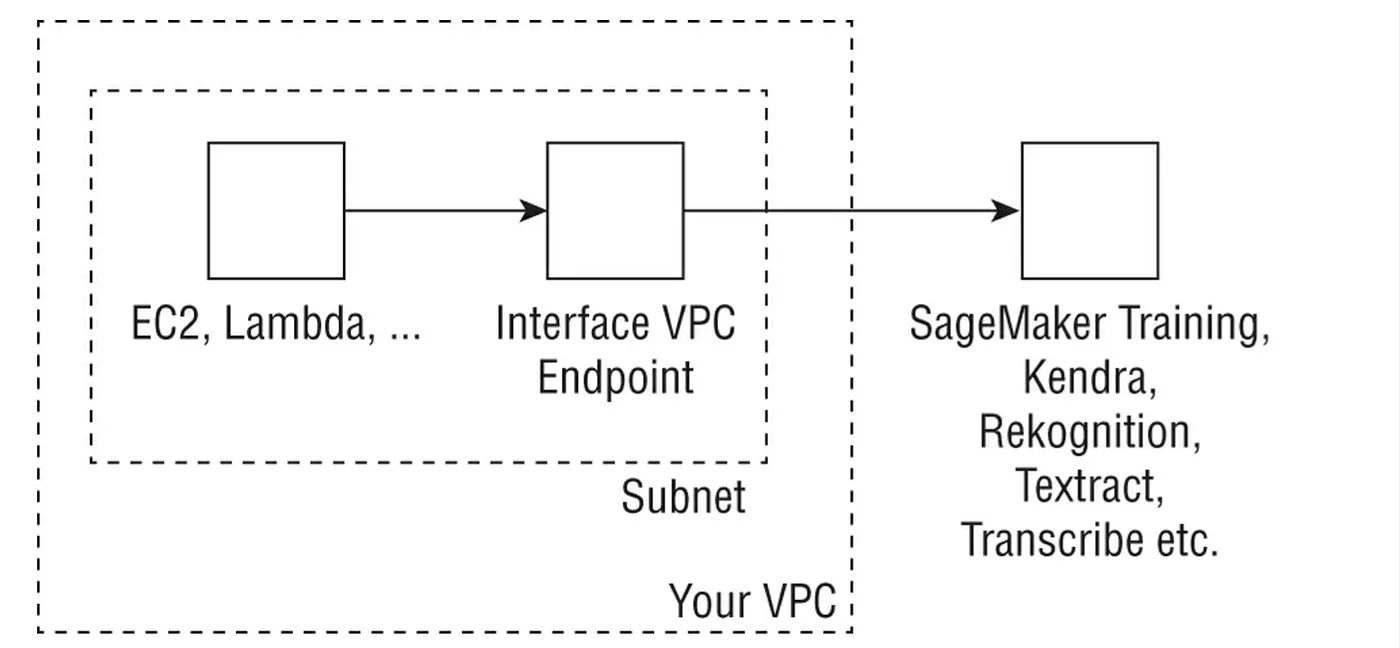
讓我們看一些關於設定VPC endpoint更細節的部分,我們使用endpoint要來access Comprehend API。我們可以在CLI介面輸入 command: create-vpc-endpoint或在AWS的 Comprehend console。不管是哪一種,我們都需要提供 VPC ID,會使用endpoint的subnets,還有這個subnet中endpoint netowrk interface會關連到的security group。在以下範例中為了限制 VPC 中的entity 只能呼叫Comprehend API的 DetectEntities API call,我們可以加上以下的endpoint policy:
AWS Lambda
Lambda是一個serviceless服務,讓我們直接將我們的code放上去跑而無須管理任何Infrastructure。我們可以在上面運行Python, Node.js, Go, Java, C#, Ruby, PowerShell或這是任何自定義的runtime; 我們可以使用docker build出來的容器跑在Lambda服務中。
Lambda可以被來自 API gateway,SNS Toipic,S3 bucket change, DynamoDB streams等event 來trigger 啟動。Lambda還可以進行大規模的運作,從一天只有幾個request到每秒數百個request(可以被平行處理)。
下表是我們在使用Lambda的一些數量限制。
有兩種較普遍的權限種類在我們使用Lambda function會用到:
execution role是指我們正在使用的Lambda function可以存取甚麼樣的AWS services與resource; resource-based policies則是反過來,那些AWS account或AWS service可以呼叫我們的Lambda函數。以下讓我們看一個清楚的範例來分辨兩者的不同。
以下的execution role讓我們的Lambda可以push log到CloudWatch中(包含了當我們create Lambda函數的basic execution role)。與Push 一個SNS topic:
另一方面,resource-based policy可以讓我們SNS可以呼叫我們的Lambda函數(把SNS trigger可以檢視這個resource-based policy):
在AWS中使用ML的客戶,通常會用Python or Node.js放在Lambda中運行。以下是一個用Lambda函數來啟動SageMaker endpoint的代碼範例:
上面的代碼範例中,首先我們在Boto3(AWS Python SDK)初始化了SageMaker runtime client,接著使用了三個參數來呼叫invoke_endpoint function:
Lambda會自動的監控我們的Lambda函數並把相關的監控指標與log寫到CloudWatch。AWS Lambda也在console提供監控圖表來記錄每次Lambda啟動的次數與時間,還有任何的throttles,delivery failures與error traces。
Serverless Object Detection案例:
一位客戶希望使用 AWS components以serverless的方式偵測圖片中的物體。 我們可以設計如下圖所示的架構,其中將圖片上傳到 S3 中的特定位置(會觸發 Python Lambda函數),這個函數首先執行一些必需的預處理並使用 Boto3 SDK 來呼叫 detect_labels API call,這個API call return 真實的instance — 在圖片中發現物體。 返回的label是階層式的(例如,運輸 > 車輛 > 汽車)並且包括confidence score以及bounding box information。 需要記得這個函數的execution role要能夠有detect_labels 操作權限。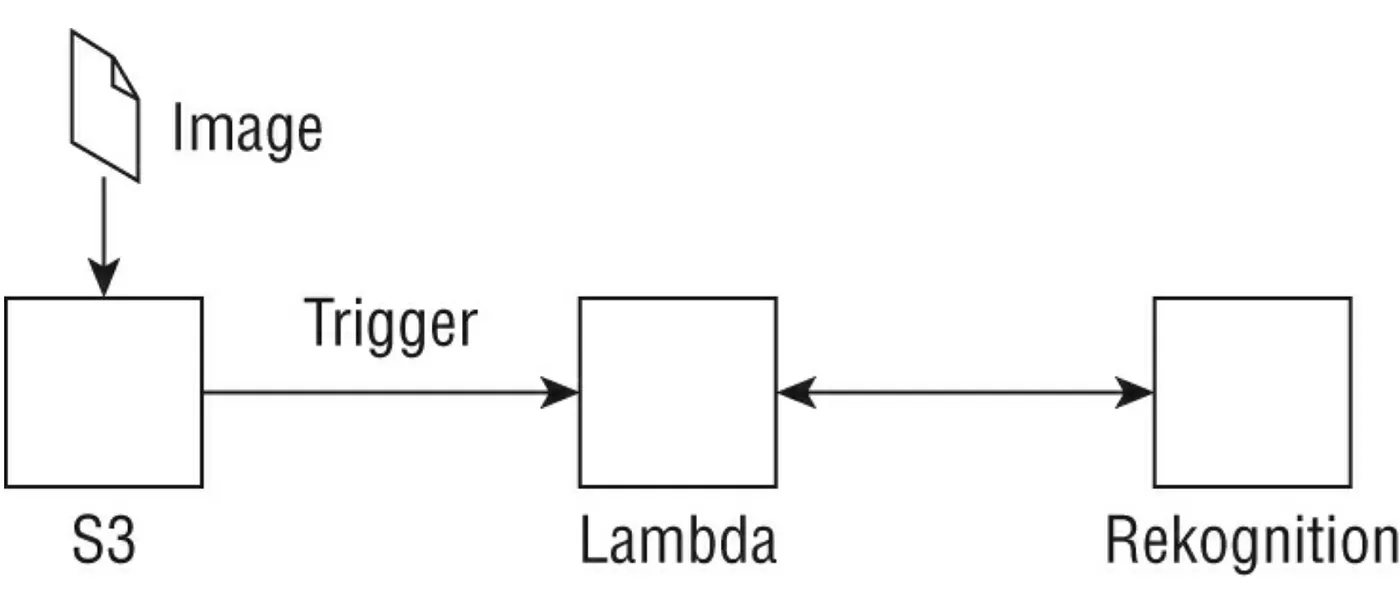
AWS Step Function
現在我們已經了解了 Lambda 工作原理的基礎知識,我們可以開始想一下如何編排一系列 Lambda函數來啟動 AWS 上的各種服務(或涉及啟動其他service的步驟)。 AWS Step Functions 是一種serverless function orchestration,可讓我們使用內建的operations controls來管理複雜的分佈式Application。 Step Functions 允許我們使用 AWS state machine 使用JSON file 的方式定義出 state machines,其中每個狀態都可以將上一步的輸出資料傳遞給我們的microservices或 AWS service integrations,例如 DynamoDB、SNS、Athena、Glue、EMR, 或 SageMaker等。 AWS Step Functions 讓我們可以監控我們的state machine,具有內建的error handling功能,並保存我們運行的每個execution的歷史記錄。
讓我們看一下State types一些比較細節的部分,這些部分包含到我們step function workflow:
讓我們看一下由下圖使用step functions,Lambda還有SageMaker 所組成的 ML workflow。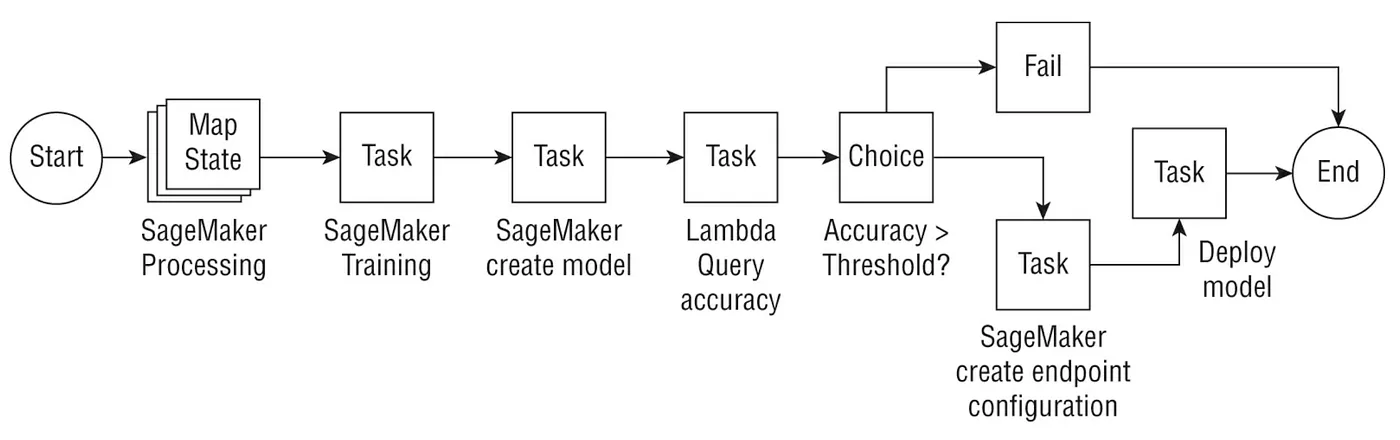
上圖中,首先我們使用Map state來運行數個 SageMaker processing job來平行的預處理(preprocessing)資料; 之後我們用 SageMaker訓練一個model,並且使用 CreateModel API來建立Model。再來使用一個自訂義的Lambda函數來 query一個精確的training job(validation),還有假如精準度是大於Predefined threshold(Choice state),例如大於85%, 我們就建立一個 SageMaker endpoint configuration並且部署模型,如果沒有(Fail state),模型就不部署。
AWS RoboMaker
AWS RoboMaker 允許我們使用ROS(Robot Operating System) 框架大規模創建robotic application,並將其擴展到其他雲端服務,例如用於ML的 SageMaker。 RoboMaker 為我們提供雲端機器人開發環境,具備模擬能力,在雲端測試這些機器人。
哪ROS究竟是什麼?ROS是一組software library與 tool協助我們build robots. 這些ROS的核心元件包含了訊息傳遞的通訊介面,robot-specific lbraries如 一個 標準description language, remote procedure calls, mapping, naviation, pose estimation與診斷,與模擬並視覺化的機器人.
通常,我們的 ROS setup 包括從source 安裝許多package,並選擇我們要在 AWS 上的哪個服務(例如,EC2 instance、container)運行開發環境和模擬。 借助 AWS RoboMaker,我們可以使用 Cloud9 insatcne,這個insatnce已經整合了開發robot application所需的工具。 遵循的典型步驟是在此開發環境中建立custom application(包括一個場景中的機器人、地形和其他資產),開發模擬環境並在模擬作業中進行測試,最後,如果需要,使用 AWS Greengrass 部署這些Application 到robot fleets。 雖然我們可以以獨立的方式使用我們的模擬環境,但通常也將其與 SageMaker 結合使用,例如,與reinforcement learning job一起使用。
案例: 模擬真實工廠的設置
客戶想要了解在客戶的工廠內的機器中使用哪些設定來最大化throughput(每小時生產的單位)。客戶的資料科學家團隊首先在 ROS 中建立了工廠的模擬版本,並在 AWS RoboMaker 中測試這些模擬。 RoboMaker 被配置為模擬工廠中固定數量的生產小時數。 Amazon SageMaker 可以與 AWS RoboMaker 交互以使用reinforcement learning(RL)訓練一個model policy。訓練完成後,RL agent可用於模擬全天中的哪些action sequence可以最大限度地提高production throughtput。
在下圖中,SageMaker RL 可用於訓練 RL agent,其中單一個training instance在多個simulation instances(稱為“rollout”instances)中產生模擬作業。這裡訓練中使用的instance type可能與 rollout instance不同。我們可以想到,某些類型的模擬作業可能需要 GPU instance type,而在每組模擬之後update模型的training instance可能是general-purpose instance。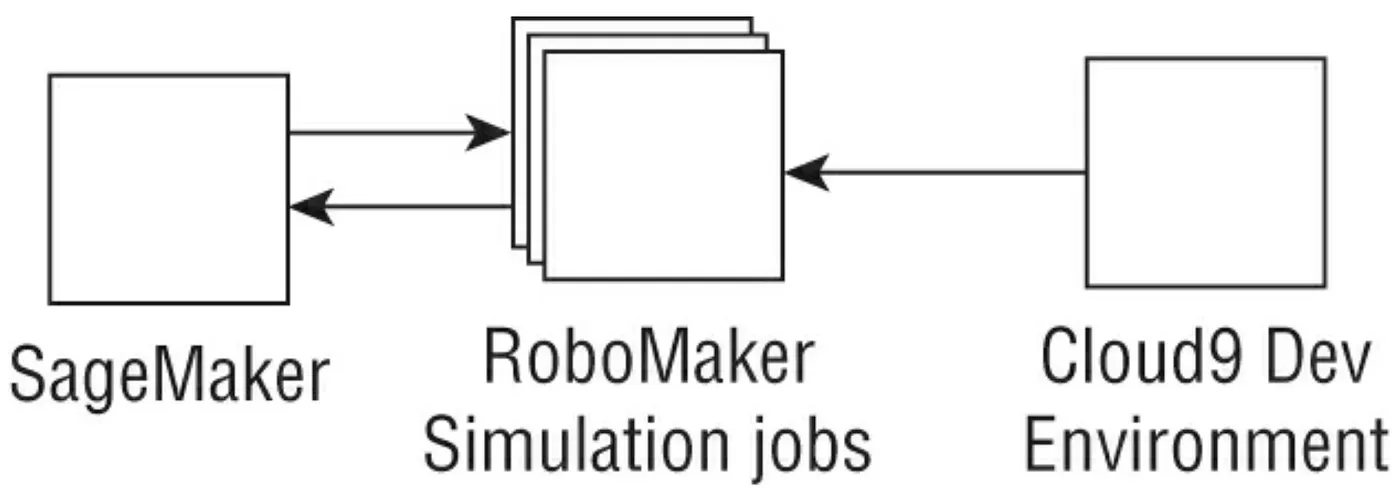
總結
本文中,我們涵蓋了支援 ML workflow的服務,例如存儲服務(如 S3、 EFS 和 FSx for Lustre)以及serverless components(如 AWS Lambda 和 Step Functions)。 這些服務是涉及 ML 的production架構的重要組成部分。
 不明
不明

 iThome鐵人賽
iThome鐵人賽